
AI神色的失败常常被悔恨于模子或算力,但实在致命的是交游数据的造作处理。从数据集中埋点到分散漂移,从噪声稠浊到合规踩雷,本文深度领悟四种典型死法背后的数据根源,揭示为什么90%的AI神色都倒在团结条起跑线上——并给出居品司理必须介入的四大致道节点。

往时一年,我密集地读了好多AI居品失败的复盘著述,也跟不少作念过AI神色的居品司理聊过。
我发现一个有道理的规章:这些神色的死法,惊东说念主地相似。
模子换了一个又一个,版块迭代了十几轮,Demo后果看起来很漂亮,但上线之后后果崩了,业务方澌灭,团队复盘时彼此甩锅。
名义上的死因各不交流——需求没对王人、算法选型错了、工程落地慢。但当我把这些案例阻隔来看,发现简直总共问题都能追意象团结个根源:
不是模子不够好。是交游数据,从一运转就错了。
我入行两年,见过的神色未几,但这件事我思恰当说澄澈——因为它简直莫得东说念主在居品司理的视角下讲透过。
一、为什么人人总把锅甩给模子,却残暴了数据?
每次AI神色出问题,复盘会上最常听到的几句话是这样的:
“咱们用的模子架构太老了,换个Transformer试试。”“算力不够,特征没跑完满。”“业务方需求一直在变,数据跟不上。”
这些说法并非统统造作,但它们有一个共同的特质——都在隐藏一个更压根的问题:喂进模子的数据,自己是否可靠?
机器学习有一条铁律,在业内被称为”GarbageIn,GarbageOut”——垃圾进,垃圾出。模子骨子上是一个放大器,它放大的不是你的盼愿,而是数据自己的质地。数据好,模子把好信号放大;数据烂,模子把噪声和偏差放大。
但奇怪的是,在大多数AI神色的启动阶段,居品司理和算法工程师的隆重力简直全部聚合在模子选型和功能遐想上,数据准备被默许为”数据团队的事”,常常到了特征工程阶段才发现问题,而这时候距离上线可能只剩两个月。
在所稀有据类型中,交游数据是被残暴得最透顶、代价也最惨重的一类。
为什么这样说?因为交游数据在大多数公司里有一个自然的”身份错位”——它在财务部门是账单,在数据团队是活水,在业务部门是GMV报表。莫得东说念主把它行为AI居品的中枢原材料来对待,也莫得东说念主从AI居品遐想的角度去界说它应该长什么样。
而恰正是这种残暴,埋下了神色失败的种子。
二、交游数据到底是什么?先把宗旨说澄澈
在潜入讲问题之前,我需要先把交游数据这个宗旨说澄澈,因为好多东说念主对它的和会停留在”订单表”这个层面,这个领路自己就依然变成了蚀本。
交游数据的界说,远比一张订单表复杂。
从AI居品的视角来看,交游数据是指用户在居品中完成或尝试完成某种价值交换行为时,系统所记载的全部信号集聚。这里的”价值交换”不仅仅付款,它包括:加购、储藏、下单、支付、取消、退款、评价、复购……每一个节点都是信号,每一个节点的缺失都是蚀本。
一条完满的交游数据,至少应该包含以下中枢字段:
时刻戳:精准到毫秒级,用于时序建模和及时风控
用户ID:关联用户画像与行为序列
商品/处事ID:关联内容特征与品类体系
交游金额:原价、实付、优惠金额需分开记载
情状流转:从待支付到已完成到已退款,每个情状变更都是零丁信号
开发信息:用于风控与多端行为交融
但更要紧的,是和会交游数据的生命周期。一条交游数据从业务发生到实在不错被模子使用,要履历一条相当漫长的链路:

这条链路上的每一个节点都可能出问题,况且越靠前的问题,代价越大——因为它会稠浊整条链路下贱的总共要领。
有一个领路我认为终点要道,需要在这里单独强调:交游数据不仅仅财务记载,它是用户真实意图最真挚的镜子。
用户不错在问卷里撒谎,不错在驳倒里花言巧语,但他们的交游行为——买了什么、在什么时刻买、买了若干、最终有莫得退——这些行为是真实意图的平直投票。这亦然为什么交游数据在所稀有据类型中,信号密度最高、交易价值最大。
三、我见过的四种典型”死法”
好,宗旨讲完毕。刻下来说说那些神色到底是若何死的。
我把它们归纳成四种典型死法,每一种背后都指向交游数据的一个具体问题。
死法一:数据集中就埋错了
这是最常见、亦然最袒护的死法。
有一个作念用户复购猜想的神色,算法团队拿到数据后发现,退款记载里的”退款金额”字段有快要40%的数据是空值。原因是什么?因为当初作念埋点的工程师认为”退款金额等于订单金额,没必要单独记”,是以这个字段从来莫得被正确集中过。
但在本质业务中,部分退款(用户只退了订单中的部分商品)和全额退款的业务含义统统不同,对用户夸口度和复购意愿的影响也人大不同。这个字段的缺失,平直导致模子无法分离这两种用户,猜想肃除严重失真。
更倒霉的是,这个问题在神色启动时莫得东说念主发现,直到模子磨砺了两个月之后作念特征分析才暴露出来。
埋点遐想的问题,是AI神色最难被提前发现的风险,但亦然最致命的风险。因为它意味着你需要再行集中数据,而数据是随机刻窗口的——历史数据补不回归,神色周期平直拉长。
字段缺失仅仅其中一种情况,口径不调处不异危急。比如”成交时刻”这个字段,有的系统记的是用户点击支付的时刻,有的记的是支付网关回调得手的时刻,两者之间可能进出几秒到几分钟。在及时风控场景里,这几分钟的各别可能平直导致特征打算造作。
死法二:数据是旧的,宇宙是新的
这个死法愈加袒护,因为它常常在神色上线之后才运转显现,况且推崇出来的症状是”模子后果缓缓变差”,很容易被误诊为”模子需要再行磨砺”。
实在的病因叫作念分散漂移(DistributionShift)。
用一个真实场景来评释:某电商平台在2023年用历史交游数据磨砺了一个智能订价模子,磨砺数据的时刻窗口是2021年到2022年。但2023年平台作念了一次大界限的品类推广,新增了无数客单价在500元以上的高端商品。这些商品的用户购买行为模式与原有品类统统不同,但模子统统莫得见过这类交游数据,当然也无法为这部分商品给出合理的订价提议。
肃除是:模子对新品类的订价合手续偏低,平台在这部分商品上的毛利蚀本了快要15%,而这个问题在上线后整整三个月才被发现。
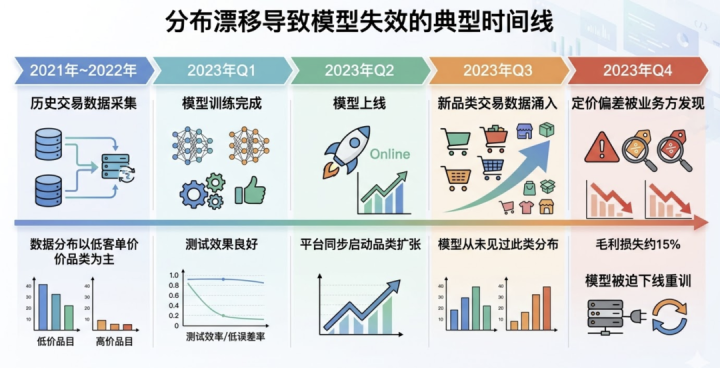
交游数据有一个特殊的时效性问题:用户的花费行为会跟着市场环境、平台政策、外部事件的变化而合手续演变。一个在特定时刻窗口内磨砺出来的模子,若是莫得合手续的数据更新机制,它的”宇宙不雅”就会越来越过时于真实宇宙。
这不是模子的问题,ued中国官网是居品司理在遐想阶段就莫得把数据更新政策纳入居品决策。
死法三:数据量很大,但全是噪声
“咱们有五年的交游数据,总量杰出10亿条。”
这句话在AI神色启动会上听起来终点令东说念主昂然。但我每次听到这句话,都会多问一个问题:这10亿条里,有若干是干净的?
交游数据的稠浊源比你思象的多得多:
刷单数据是最典型的稠浊源。在电市集景里,刷单行为会产生无数乌有的”高质地用户”信号——这些账号的购买频次高、客单价踏实、简直不退款,看起来是模子最可爱的优质用户特征。但若是这些数据进入磨砺集,模子学到的即是刷单行为模式,而不是真实用户行为。
测试数据是另一个常见稠浊源。好多公司的测试环境和坐褥环境共用团结套数据管说念,测试账号产生的交游数据若是莫得被正确过滤,就会混入磨砺集。我见过一个神色,磨砺集里有快要8%的数据来自里面测试账号,这些账号的行为模式相当额外(比如一天之内下了200单又全部退款),平直拉偏了模子对平素用户行为的判断。
促销期额外数据也需要额外处理。双十一、618等大促时期的交游数据,用户的购买行为受到价钱刺激,与日常行为模式各别极大。若是不加分离地把这部分数据混入磨砺集,模子会高估用户的价钱明锐度,导致日常场景下的保举和订价政策出现系统性偏差。
数据量大给了团队一种乌有的安全感,让东说念主以为”样本够多,模子当然会学好”。但在噪声主导的数据集里,模子学到的仅仅噪声的规章。
死法四:合规红线踩了,神色平直叫停
这是四种死法里最”冤”的一种,因为它常常发生在神色依然作念了泰半、致使依然上线之后。
交游数据自然触及用户的财务阴私,在《个东说念主信息保护法》和GDPR的框架下,对交游数据的集中、存储、使用都有明确的合规条款。但好多AI神色在遐想阶段统统莫得法务介入,居品司理和算法工程师按照”时期上能作念什么”来遐想决策,而不是”法律上允许作念什么”。
常见的踩雷点包括:未经用户明确授权就将交游数据用于画像建模;跨业务线分享交游数据时莫得作念数据进攻;将含有个东说念主身份信息的交游数据平直用于模子磨砺而未作念脱敏处理。
我见过一个金融科技公司的AI风控神色,在上线半年后因为沿路用户投诉,被监管机构介入审查,最终发现神色在数据使用授权上存在要紧劣势,总共这个词系统被强制下线整改,前期参加全部取水漂。
合规不是法务部门的事,是AI居品司理在遐想阶段就必须完成的作业。
四、交游数据实在用对了,能作念到什么?
说了这样多失败案例,我也需要说说,当交游数据被正确对待时,它能为AI居品带来什么。
个性化保举:从”猜你可爱”到”预判下一单”
传统的协同过滤保举依赖的是用户的静态偏好(买过什么、看过什么),而基于交游序列的深度保举模子,好像捕捉用户购买行为的时序规章。
比如,一个用户在往时三个月里按照”联接鞋→联接袜→联接裤→联接上衣”的步履完成了四次购买,模子不错从这个序列中学到”这个用户正在缓缓完善联接装备”的意图,并不才一次触达时主动保举他还短缺的品类,而不是继续推他依然买过的东西。
这种基于交游序列的意图猜想,比点击行为数据准确得多,因为付款行为是用户意图最强的阐发信号。
及时风控:毫秒级决策背后的数据逻辑
及时风控是交游数据价值密度最高的利用场景之一。一笔额外交游的识别,需要在用户点击”阐发支付”到支付网关处理完成的几百毫秒内完成判断。
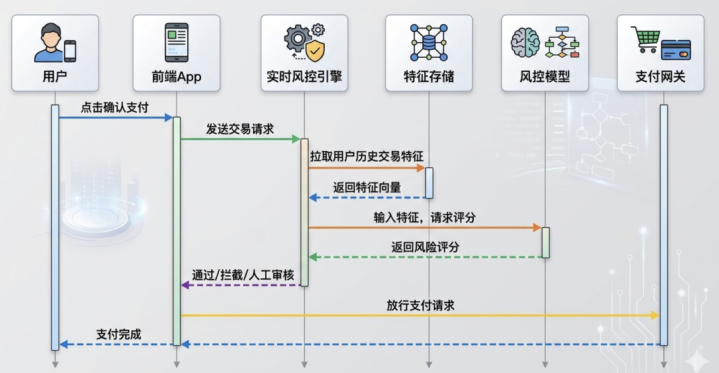
这个链路的每一个要领都依赖高质地的交游数据:历史交游特征需要及时更新,特征存储需要撑合手毫秒级读取,模子需要在极低延伸下完成推理。任何一个要领的数据质地问题,都会平直影响风控的准确率和用户体验。
用户价值分层:RFM模子的AI进化旅途
经典的RFM模子(最近一次花费、花费频率、花费金额)是基于交游数据作念用户分层的经典方法。但传统RFM是静态的、基于章程的,而AI化的RFM不错作念到动态猜想。
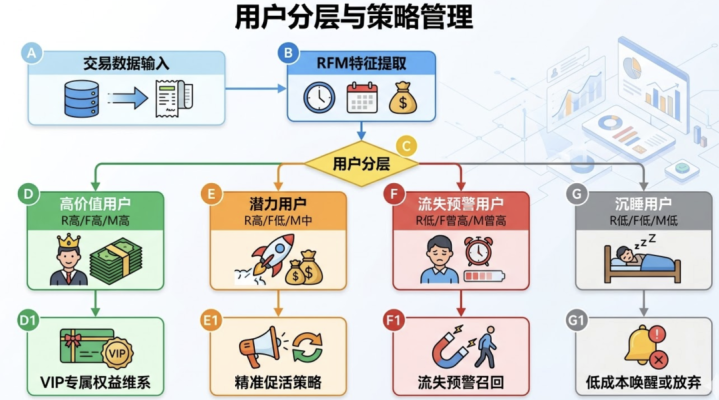
AI化的进阶之处在于:它不仅仅态状用户”刻下是谁”,而是猜想用户”改日会若何”。基于交游序列,模子不错猜想一个用户在改日30天内流失的概率、下一次购买的品类偏好、以偏激生命周期总价值(LTV)。这让运营政策从”过后反应”变成了”预先干豫”。
智能订价:弹性订价与补贴政策的数据基础
价钱明锐度建模是交游数据最平直的交易利用之一。通过分析不同用户群体在不同价钱区间下的购买飘零率,模子不错为每个用户、每个商品、每个时刻段打算出最优订价区间。
这不是简单的”打折促销”,而是基于交游数据对用户支付意愿的清雅化建模。一个作念对了智能订价的平台,不错在不裁汰全体GMV的前提下,显耀进步毛利率——因为它知说念哪些用户对价钱不解锐,不需要给他们发优惠券。
五、AI居品司理当该在哪些节点介入交游数据?
说到这里,我思平直给出一个可践诺的行动框架。作为AI居品司理,你需要在神色的四个要道节点主动介入交游数据的处分,而不是等着数据团队”准备好了再来找你”。
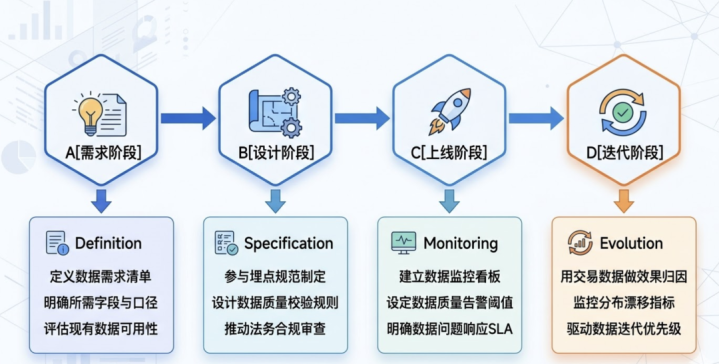
需求阶段是最要道的介入节点。在神色立项时,居品司理就应该输出一份数据需求清单,明确AI功能所需的每一个字段、口径界说、数据时效要乞降历史数据覆盖周期。这份清单需要与数据团队对王人,阐发现存数据是否恬逸需求,若是不恬逸,补集中的周期是多久——这平直决定神色的可行性和时刻线。
遐想阶段,居品司理需要参与埋点法度的制定,而不是把它统统甩给工程师。埋点文档应该是居品遐想文档的一部分,明确每个交游节点需要集中哪些字段、字段的数据类型和陈设值是什么、额外值如哪里理。同期,这个阶段必须鼓励法务部门完成数据合规审查,阐发数据使用现象合适关联法例条款。
上线阶段,居品司理需要鼓励建立数据监控看板,将数据质田主张(字段完满率、额外值比例、数据延伸)与模子后果主张放在团结个视图下监控。当数据质地出现问题时,需要有明确的告警机制和反应经由,而不是比及模子后果崩了才去排查原因。
迭代阶段,用交游数据作念后果归因是AI居品司理最容易被残暴的才调。好多东说念主在迭代时只看模子的离线主张(AUC、NDCG等),但这些主张和业务肃除之间的干系并不服直。应该建立从交游数据起程的归因链路,搞澄澈模子的哪些猜想肃除最终飘零成了真实的业务价值,哪些莫得——这才是驱动下一轮迭代标的的正确依据。
结语:烂尾的从来不是AI,是对数据的自高
我写这篇著述,不是为了给AI泼凉水。碰巧相背,我终点坚信AI在居品中的价值,也见过它实在阐明作用时的形势。
但我也见过太多东说念主把AI神色的失败归因于时期不够教训、算力不够强、模子不够先进。这些原理随机候是果然,但更多时候,它们是一种体面的说法,用来掩盖一个更难承认的真相:咱们莫得恰当对待数据。
交游数据是AI居品的地基。地基没打好,楼盖得越高,倒得越快。
启动一个AI神色,问我方的第一个问题不是”咱们用什么模子”,而是:
“咱们的交游数据准备好了吗?”
好的AI居品司理,是从数据运转遐想居品的,而不是从功能运转。这不是一句标语,是我见过充足多的失败之后UED体育中国官方网站入口,得出的最朴素的论断。
米兰体育(MilanSports)官网 备案号:
备案号: